Convolutional neural network (CNN)
31 minutesConvolutional Neural Network (CNN) is a type of deep learning model designed for processing image data. It is commonly used for image recognition, classification, and feature extraction. In medical applications, CNNs can help analyze medical images and detect tumors or lesion regions.
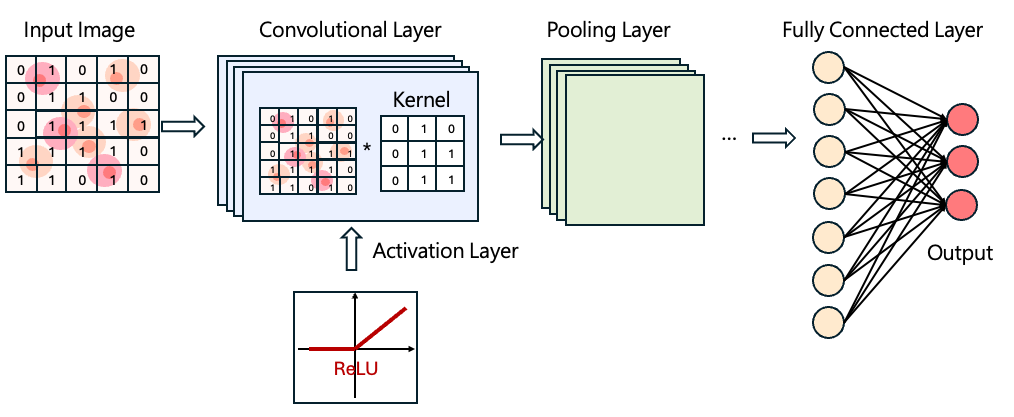
The basic structure of a CNN includes the following layers:
Convolutional Layer
In the convolutional layer, a small matrix called a kernel (or filter) is used to slide across the image. As the kernel moves over the image, it extracts key local features from each region.
Activation Layer
Typically following a convolutional layer, an activation function introduces non-linearity to the model. A commonly used activation function is ReLU (Rectified Linear Unit, \(f(x)=max(0,x)\)). Introducing non-linearity enables CNNs to learn more complex patterns and improves model performance.
Pooling Layer
The pooling layer reduces the dimensionality of the feature maps output from the convolutional layer. Methods such as max pooling or average pooling help reduce computational load while retaining the most important information.
Fully Connected Layer
he fully connected layer converts the extracted features into final classification results. For example, in image classification tasks, it outputs the probability of an image belonging to each category and determines the final prediction.
Common CNN Architectures
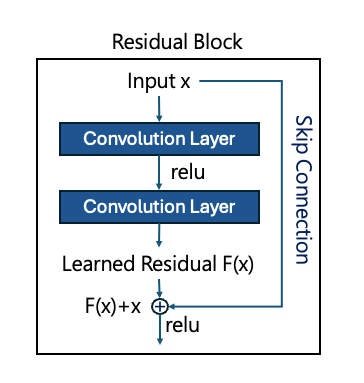
1. ResNet
ResNet was developed to address the vanishing gradient problem in traditional CNNs. As CNNs grow deeper, gradient information may diminish, making training less effective.
To solve this, ResNet introduces residual blocks. Simply put, every few layers, a shortcut connection passes the input x directly to the output, allowing the model to learn the residual F(x) instead of the full transformation. This design preserves important features during training and enables efficient training of very deep networks.
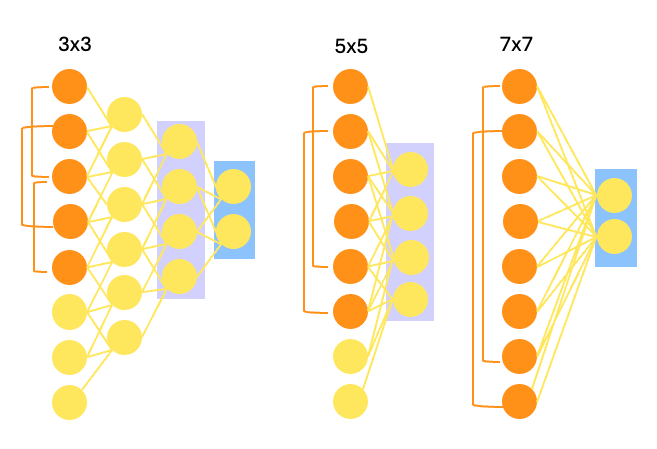
2. VGG
VGG architectures use smaller convolutional kernels (3×3) and pooling layers (2×2). As shown in the diagram, stacking multiple small kernels achieves the same receptive field as larger kernels (5×5 or 7×7) while enabling deeper networks to extract more detailed features.
Popular models include VGG-16 and VGG-19, which contain 13 or 16 convolutional layers plus 3 fully connected layers. Pretrained ImageNet weights are available, making these models suitable for general image classification tasks.
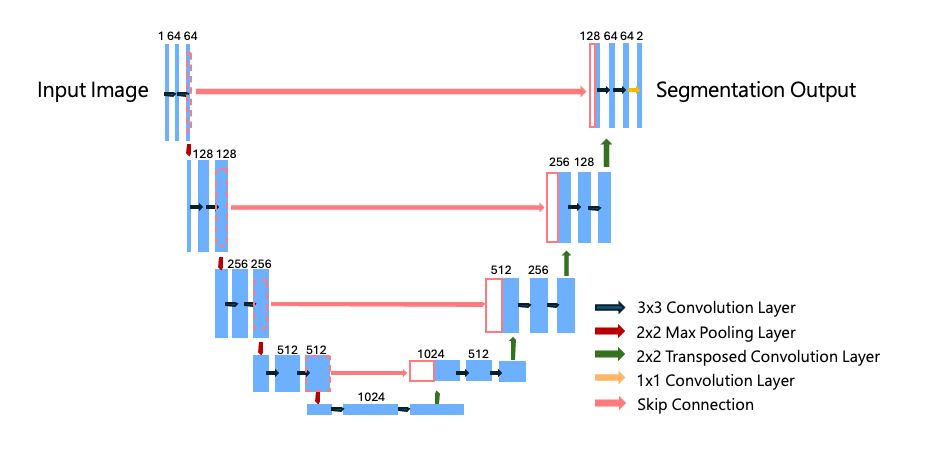
3. U-net
U-Net is widely used for medical image segmentation. It addresses challenges such as high image resolution and limited training data. The U-Net consists of two main parts:
-
an encoder for feature extraction
-
a decoder for upsampling
These are connected through skip connections, which pass encoder features to the decoder to preserve local details — crucial for high-precision medical segmentation.
Different depths of layers capture different receptive fields, enabling the model to see both fine details and broader context. This makes U-Net highly effective for medical imaging tasks where both cell morphology and spatial location are important.
Practical Applications of CNNs
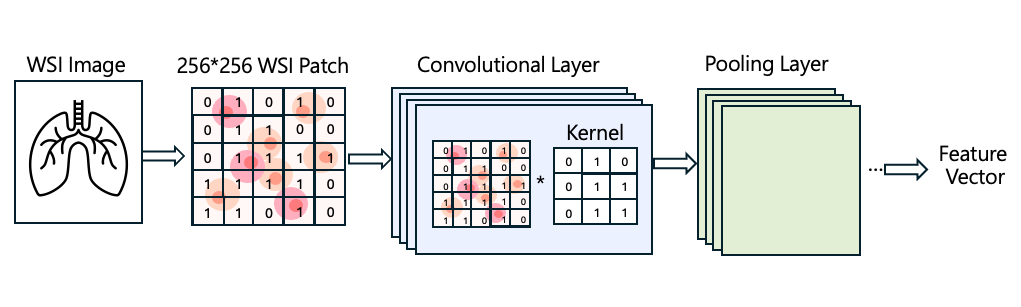
You may first read: CLAM: Feature Extraction
In CLAM, WSI tiles are processed using a CNN. During image processing, convolutional kernels move across the tissue image, extracting patterns based on texture, morphology, and color variations. The network keeps only the most informative features. Through repeated convolution and dimensionality reduction, high-resolution WSI images can be converted into compact feature vectors. These low-dimensional vectors are then used for downstream model training.