模型訓練與推論
9 minutes1. 模型訓練與推論
1.1 演算法訓練
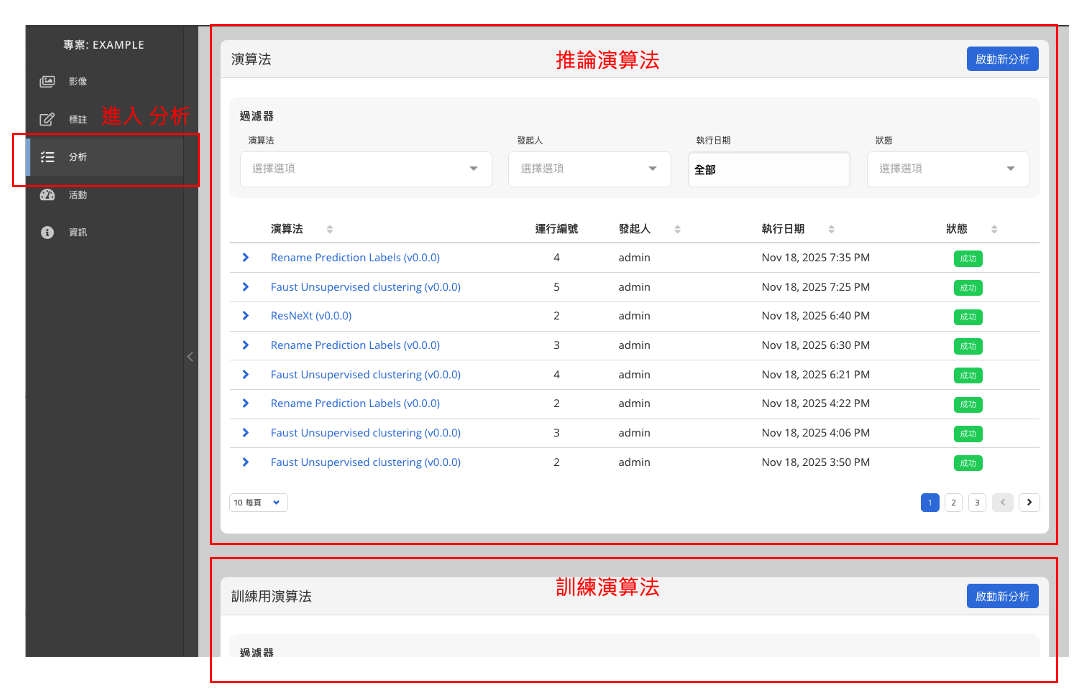
於專案頁面中,點選左側 分析 欄位進入演算法區域。
在此畫面中分為兩部分:
上方:演算法 → 用於推論
下方:訓練用演算法 → 用於模型訓練
▶ 開始訓練
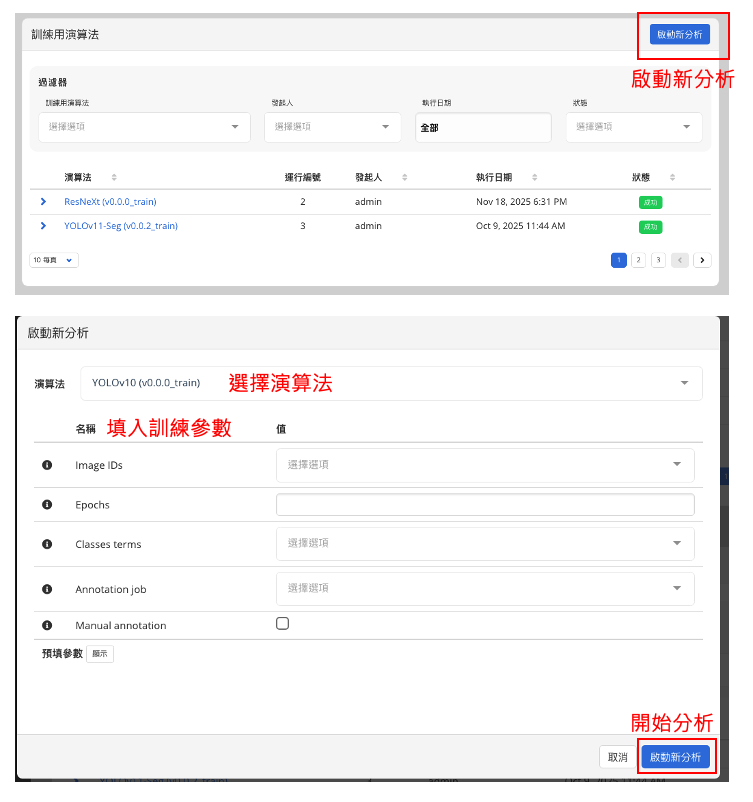
於下方 訓練用演算法 中選擇欲訓練的模型
點擊 啟動新分析 開始設定訓練任務
系統目前提供以下演算法類型:
- YOLO(物件偵測 / 影像分割)
- SAM(智慧分割)
- ResNeXt(影像分類)
▶ 訓練可設定的參數
-
訓練資料來源
- 輸入訓練影像 ID
- 或直接全選專案內影像
- 可選擇標註來源:
- 人為標註 (Manual Annotation)
- 模型標註 (Annotation Job)
-
基本訓練參數
- Epoch 數 (Epoch)
- 選擇要訓練的術語(Class Terms)
- 驗證集影像比例(Fraction of validation dataset)
- 切片大小(Patch size)
- 批次大小(Batch size)
- 學習率(Learning rate)
此區參數會根據模型類型略有差異。
1.2 演算法推論(Inference)
訓練完成後可至 分析 → 演算法 查看可用模型,並進行推論。
不同演算法會提供不同調整選項,例如:
- 信心閾值( Confidence score threshold)
- 最大偵測數(Maximum number of detections)
- 網格大小(Grid size)
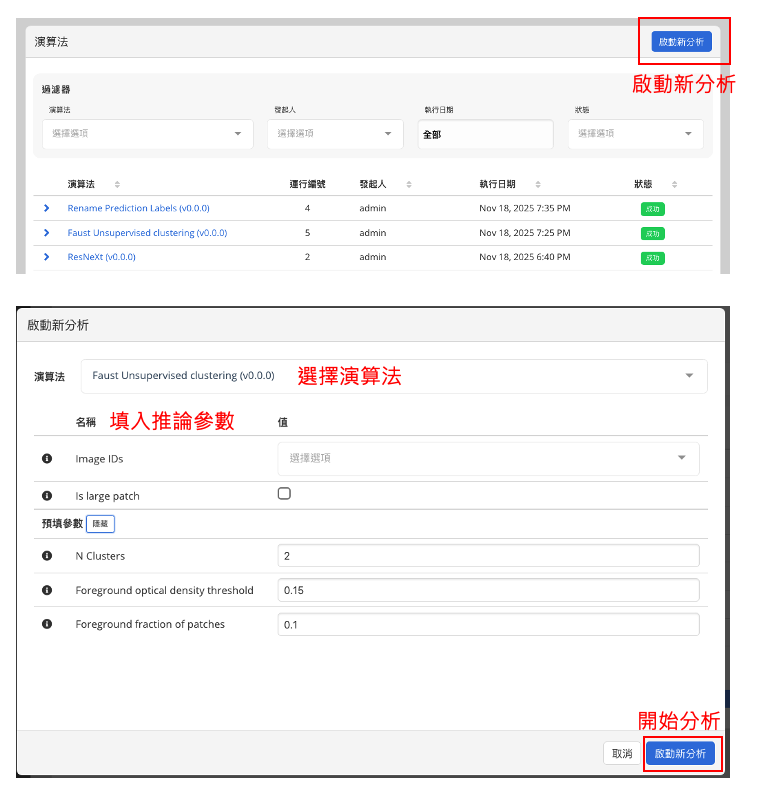
▶ Faust:非監督式演算法
平台特別提供 Faust 非監督式學習模型(說明可參考部落格與原始論文)。
Faust 需設定以下參數:
- 影像是否為大張切片 (Is large patch) → 若勾選,系統會自動將切片大小放大為一般影像的四倍
- 欲分類的群數(N Clusters)
- 前景光密度閾值(Foreground optical density threshold)
- 前景像素比例門檻(Foreground fraction threshold)
▶ 標註後處理:Rename Prediction Label
平台提供 「Rename prediction label」 任務,可將模型預測的標註重新命名:
用途包括:
- 半監督式學習流程
- 模型預測結果分類統一
- 整理多模型結果標籤