Cluster model 叢集模型
10 minutes什麼是叢集模型?
叢集模型是一種將資料自動分組的技術,是機器學習中常見的應用之一,目的是讓相似的資料點被歸類到同一組,稱為「叢集」(cluster),而特徵點相差較大的資料點則被分到不同叢集。透過叢集分析,使用者能夠分析每筆資料間的關聯性,並在處理大數據時提供方便的統計工具。
監督式和非監督式學習
機器學習大致上可以分為兩種類別,監督式和非監督式學習。在這裡,所謂「監督」是指訓練者在模型訓練過程中是否有對資料進行標註。
機器學習的流程可以簡單地敘述成 輸入學習資料→生成模型→比對結果和學習資料→調整模型 ,並透過不斷地循環優化模型功能。而能訓練出一個好的模型很大程度取決於擁有好的學習資料,當一開始丟給機器學的就是錯誤的資料,理所當然的會得到不好的學習成效,產生出不夠精準的模型。
在監督式學習時,訓練者會人工給予資料正確的標注,這使得模型在學習過程中有一個標準答案可以參考,模型的分類結果也會根據當初的標注資料訓練而成,常見的應用有像是分類、語音辨識等。相對的,非監督式學習則是訓練者完全不標註任何的訓練資料,常用於資料分群,如這篇主要探討的叢集分群。適用於使用者缺乏資歷標註時對資料關聯性的探索。
此外,還存在一種折衷的學習方式,即半監督式學習。當完全依賴非監督式學習的結果不符合預期時,使用者可以選擇為部分資料進行標註,讓機器在已有的標註資料基礎上進行進一步學習。這種方法結合了監督式與非監督式學習的優點,既能減少標註成本,又能提升模型的準確性。
常見的叢集算法
了解了資料的前置處理步驟後,接下來就可以說明一些常見的叢集方法了。
K-means 演算法
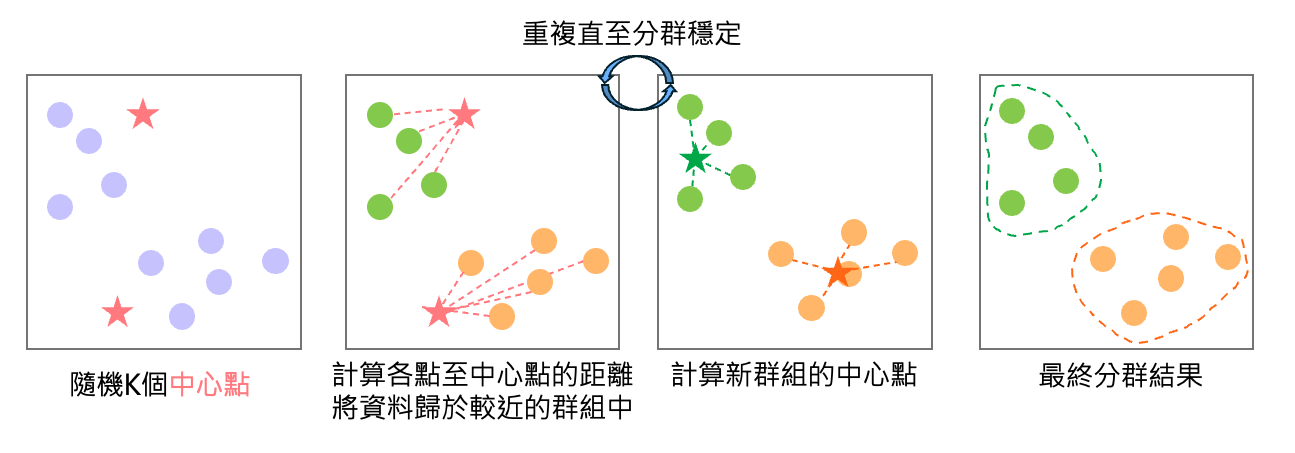
K-means演算法是非監督式學習中最常見的叢集演算法之一。其優點在於使用者可以自由的指定希望將資料分為K類。假設現在我們希望將資料分為兩類 (K=2),這時演算法會先隨機出兩個初始中心點,接者重複以下步驟:
- 計算各個資料點與中心點間的距離,將資料歸類於距離較近的中心點所在的群組中。
- 重新計算出各類別的中心點
透過幾次的循環,直到各資料點的分類穩定下來為止。
 至於如何選擇叢集的數量?有幾種常見的方法:
至於如何選擇叢集的數量?有幾種常見的方法:
- 手肘法
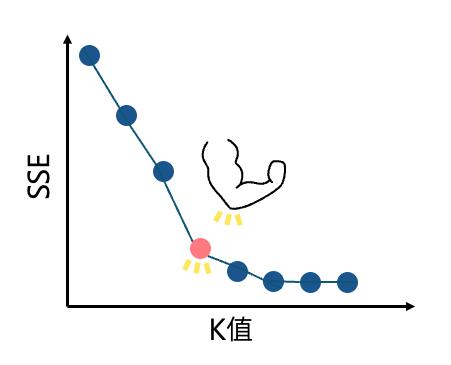
第一種常見的方法稱為手肘法(elbow method)。如同上述所說明,K-means是一種基於與中心點的最短距離進行分群的演算法,因此可以想像,在處於合理的分群數時,各個資料點至中心點的距離應該要越短越好。手肘法便是運用此概念,計算各個資料點至中心點的誤差平方和(SSE, Sum of Square Errors),並觀察K=2~N時的誤差變化,當減少幅度變得不顯著時,SSE 曲線會形成類似「手肘」的轉折點,該轉折點即為理想的 K 值。
- 輪廓法
第二種稱為輪廓法(Silhouette Method),透過計算每個資料點的輪廓係數s(i)評估分群效果,公式如下:
\(s(i) = \frac{b(i) - a(i)}{\max\{a(i),\, b(i)\}}\).a(i)表示的是點i和同群資料點的平均距離,代表群內的相似度b(i)表示的是點i和他群資料點的平均距離,代表與他群間的相異度-1<s(i)<1,越接近1表示和所在群相似度高,分群效果好,反之越接近-1表示和所在群並不相似,分群效果不佳。 我們可以透過比較不同K值下的s(i),取最大值所對應的K值,即為理想的分群數。
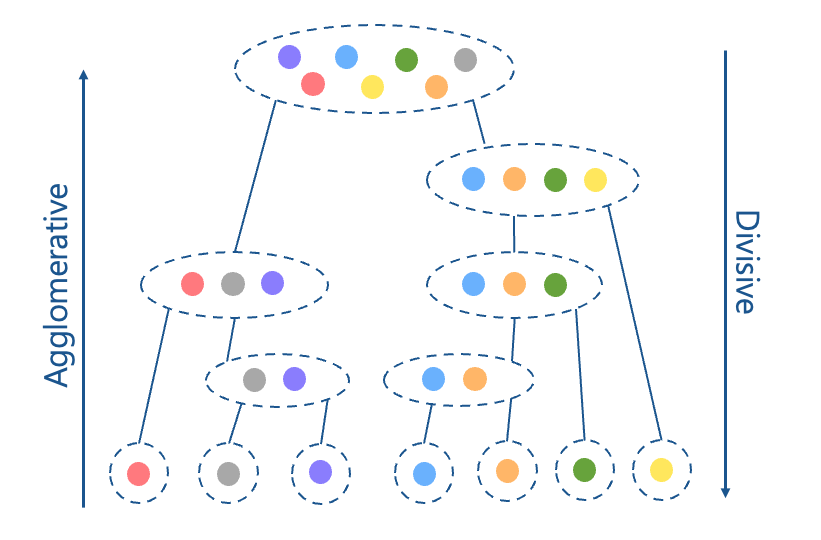
層次聚類(Hierarchical Clustering)
層次聚類是將資料組織成樹狀結構的叢集方法。有兩種建構方法:第一種是由上而下(Divisive),先將所有資料視為一個整體,再慢慢的下分為子資料群,直到最後每個子資料群都剩一筆資料為止。第二種是反過來由下而上(Agglomerative),將每筆資料是為單獨的群組,並逐步的合併成群,直到全部集合為一個群體為止。
 而如何合併資料群有幾種方法:
而如何合併資料群有幾種方法:
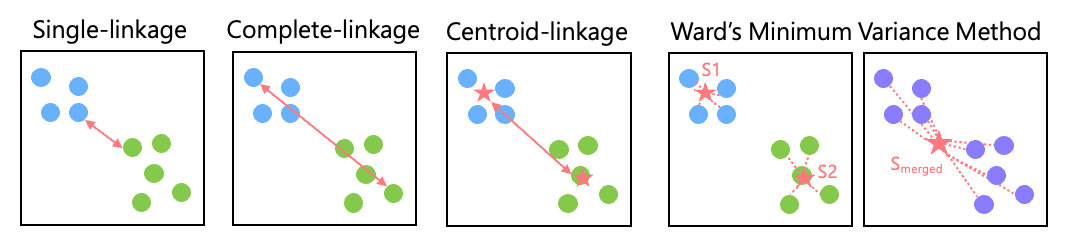
Single-linkage:計算兩個群間最近資料點的距離
Complete-linkage: 計算兩個群間最遠資料點距離
Average-linkage: 計算兩個群間所有資料點的平均距離
Centroid-linkage: 計算兩個群的質心間的距離
Ward’s Minimum Variance Method: 先計算兩個群中資料和質心的平方差S1, S2和與合併後的新質心的平方差Smerged 並得到最後的方差 DS = Smerged – (S1+S2),並將 DS最小的兩個群合併,能生成較分明且特徵明確的分群。
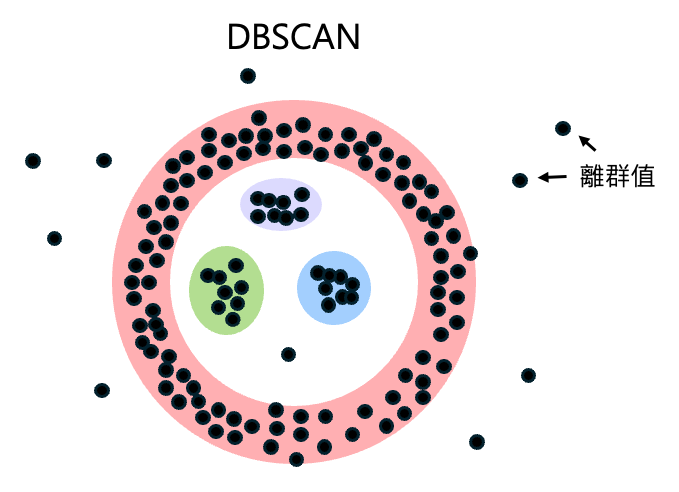
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)演算法
和上述的K-means不同的地方在於DBSCAN會根據資料密度自行分成N群,並排除一些離群值。因此當我們使用了K-means後確認為分群結果不理想或是無法決定群體數目時,DBSCAN是個很好的方法。
實際病理應用
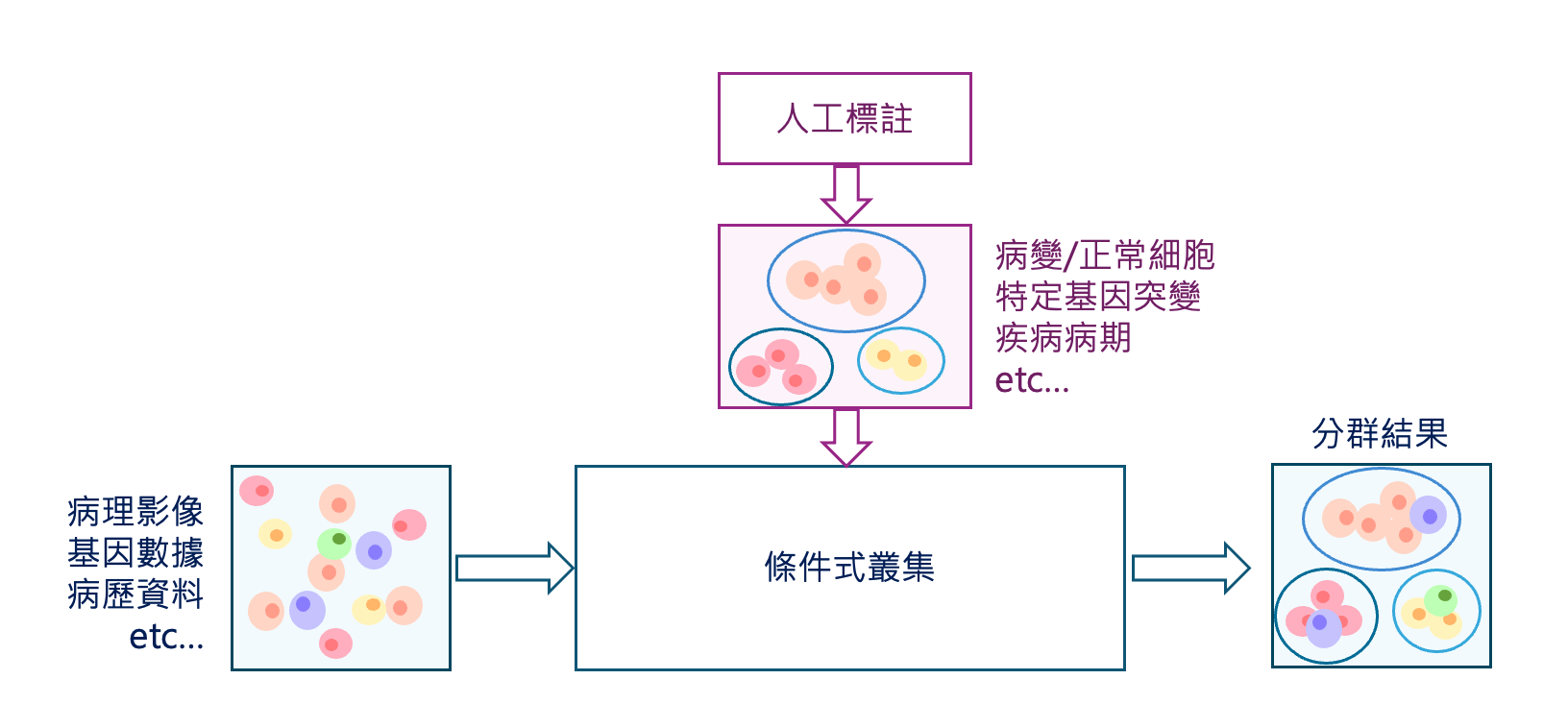
可以先閱讀 CLAM: Clustering-constrained 條件式叢集
在一般的叢集模型中,模型會自動的依據輸入資料的特徵進行分類,例如將病例作為訓練資料時,模型會自動依據病史、症狀、性別等因素將病人進行分類,這種學習模式稱為非監督式學習,意即在沒有人為標註的情況下,模型自動進行分群。此種模型的缺點在於分類的特徵並不一定重要,這時就需要使用到條件性叢集這種半監督式學習模型。在訓練半監督式模型時,需要先人工的給予標記,機器則會依據給予的標記進行學習分群。在病理影像中,這能使使用者訓練出符合需求的模型,比如分辨普通和病變細胞等,能夠聚焦於醫師關注的特定特徵。