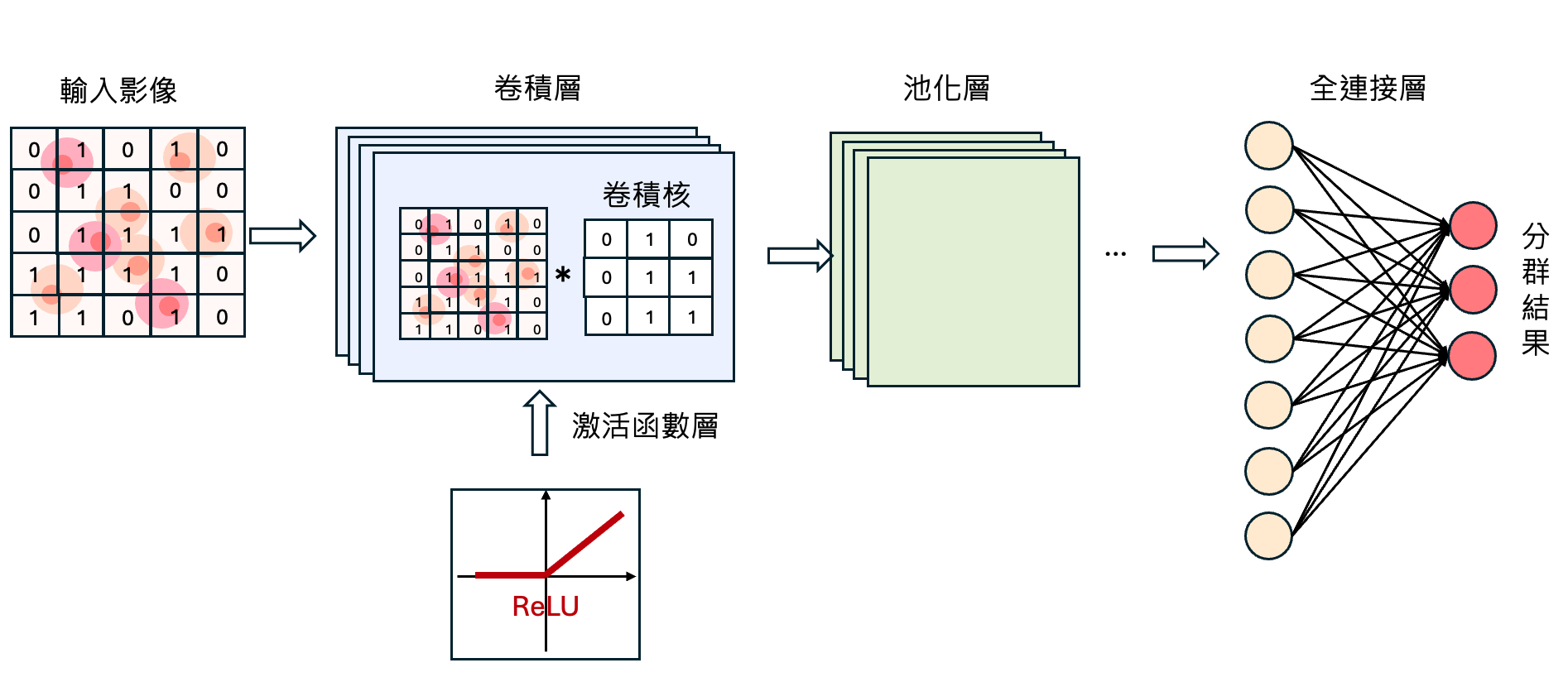
卷積神經網路模型(Convolutional Neural Network, CNN)是一種用於處理圖像數據的深度學習模型,能用於圖像辨識、分類和提取特徵等。應用於醫療中可以幫助分析醫學影像並檢測腫瘤、病變區域等。 CNN的基本結構包含以下幾層:
卷積層(Convolutional Layer)
在卷積層中,會利用一個小型矩陣,稱為卷積核 (Kernel),以滑動窗口的方式掃描整張圖像,在掃描時卷積核會提取該區域的特徵。
激活函數層(Activation Layer)
通常在卷積層之後,會使用非線性函數運算卷積層輸出,常見的函數為 ReLU (Rectified Linear Unit, \(f(x)=max(0, x)\))。引入非線性能使CNN應付更複雜的模式和提升學習的能力。
池化層(Pooling Layer)
池化層的主要作用為對卷積層的輸出進行降維。降維的方式可能為取最大或是平均值,這能降低後續的運算量同時只保留最關鍵的訊息。
全連接層(Fully Connected Layer)
最後的全連接層則負責將前面提取出的特徵轉換為分類結果,以圖像分類為例,全連接層會計算出該圖像屬於某分類的概率,並給出最終的預測結果。
常見的CNN架構模型
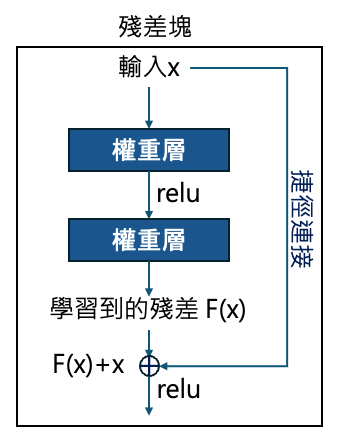
1. ResNet
ResNet 的發展源於傳統CNN模型中的梯度流失問題,在傳統的 CNN 中當模型的層數越多時,準確度將因訓練過程中梯度的流失而降低。為了解決這個問題,ResNet 模型中導入了一種稱為「殘差塊(Residual block)」的機制。簡單的來說,在Resnet中每個幾層便會透過捷徑(shortcut connection)將原先的輸入的特徵x輸入回去學習到的殘差F(x) 中,避免訓練過程重要特徵的流失。這使得Resnet能夠快速的訓練出更精準的深層網路。
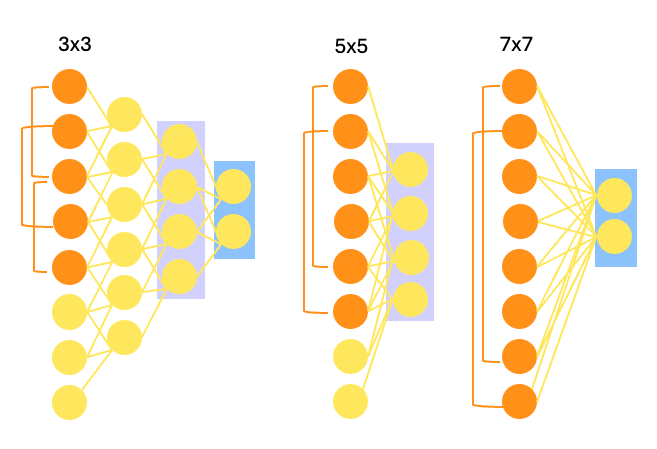
2. VGG
VGG的主要架構不同在於使用更小的卷積核(3x3)和池化層(2x2),如下圖所示,加深卷稽核的層數可以達到和 5x5 或是7x7 相同的輸出,更深的網路架構卻能提取更多的特徵。這使得模型能更加的準確,卻也更耗費運算資源。常見的 VGG 模型有 VGG-16 和 VGG-19 兩者分別擁有13和16層卷積和3層全連結層。兩者皆有使用ImageNet訓練過的參數可以使用,可輕易用於簡易的圖像分類。
3. U-net
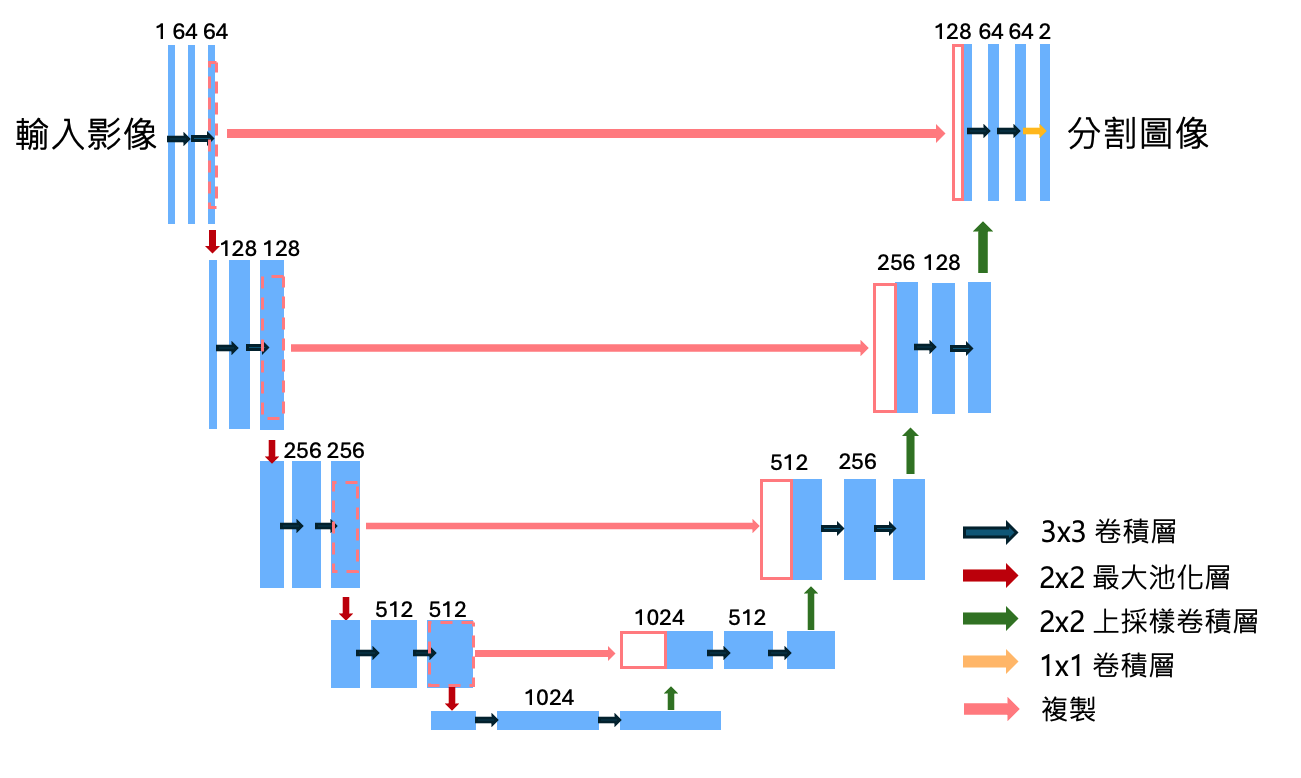
專用於分割醫學影像的模型。此模型解決了醫學影像解析度過高、數量稀少的問題。整個 U-net 簡單的分為兩個部分,提取特徵的編碼器(encoder)和負責上採樣的解碼器(decoder),中間由 skip connection 所連結,將每層 encoder 特徵輸入給 decoder,防止失去 local 特徵,幫助需要高精準度的醫學影像。而不同深度所抓到的 receptive field(可以理解為模型的視野大小)的大小也不同,越大的 receptive field 能幫助模型看到更多的背景,對於醫學影像來說也是很重要的一點,畢竟細胞本身和細胞所在的位置對醫學影像的解析來說是同等的重要,這也是為什麼 U-net 作為醫學影像分割如此的好用。
CNN的實際應用
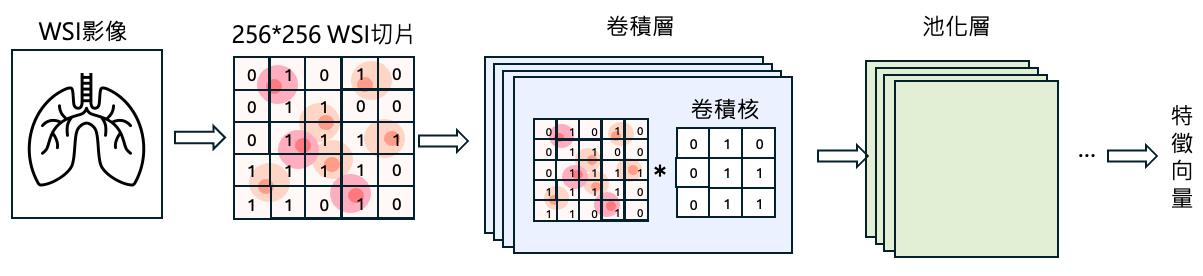
可以先閱讀 CLAM:特徵提取
在 CLAM 中,會將 WSI 的切片輸入 CNN 中。在讀取影像時,CNN 中的卷積核會以矩陣的形式小塊小塊的掃過整張影像並讀取其中的訊息,且根據型態、顏色等變化保留模型認為最重要的部分,也就是所謂的特徵。透過卷積核多次的提取特徵和對特徵矩陣的降維,我們可以把資訊量龐大的原始切片,轉換為較為低維的特徵向量。這些低維的特徵向量能夠輸入後續的模型中進行訓練。